


你的位置:kaiyun开云体育世界杯中国网页版登录入口 > 2026世界杯 > kaiyun体育网页版登录入口 当线性注宗旨学会「写入前念念考」: 并行化的多步记念写入
发布日期:2026-06-14 08:21 点击次数:199

Transformer依托强盛的建模技艺和Scaling遵守在保举鸿沟被无为应用于超长序列建模和生成式保举等标的,但
复杂度,能在不作念序列截断的情况下处理轻易长度的行为序列,
的计较支出不得不作念出多样协调:举例将self-attention改为cross-attention或local-attention、序列截断、序列压缩等。这些弃取虽缓解了计较压力,但不可幸免地赔本了序列中的长程行为模式。受LLM鸿沟线性注宗旨(LinearAttention)及羼杂架构量度的启发,线性注宗旨自然具备
可能是保举鸿沟比Transformer更匹配的底层架构。相关词,现存线性注宗旨模子每步只可作念rank-1的浅层写入,建模质料与Transformer仍有差距;而具有多步深度写入技艺的TTT(Test-TimeTraining)虽质料突破,却因串行依赖导致磨砺糊涂量比线性注宗旨慢,难以工业部署。
为此,腾讯告白时刻团队与北京大学互助建议PRISM(ParallelResidualIterativeSequenceModel)——在保抓线性注宗旨
复杂度的同期,兑现TTT级别多步深度写入的序列模子。PRISM通过分析TTT-MLP的梯度结构,揭示其高抒发力源于步长×残差×标的的多步迭代模式,并发现这一高抒发力与串行瓶颈是统一根因(权重迭代更新)的两面。基于这一知悉,PRISM在兼容parallelscan的线性景色上显式重建了该迭代模式,通过局部anchor代理扬弃token间串行,通过闭合式展望算扬弃step间串行,最终呈现为一个长入的残差拟合过程:第一步当然退化为线性注宗旨的圭臬写入,后续步以不到10%的参数增量叠加低秩修正。在四个序列保举基准上,PRISM匹配TTT质料且糊涂量擢升174倍;与一丝Transformer层构成羼杂架构后超越纯Transformerbaseline。
该责任已被机器学习鸿沟顶级会议ICML2026拜托,论文题目“PRISM:ParallelResidualIterativeSequenceModel”。
一、布景:从无尽背包到有限背包
(一)Transformer的无尽背包与线性注宗旨的有限背包
Transformer的Attention机制本色上是一个"无尽背包":它把每一个token的KV齐完好意思保存在KVCache中,推理时一一比对。这带来了极强的抒发力,但存储和计较量随序列长度N呈
增长,当坎坷文达到百万token量级时,即便顶尖GPU也难以承受。
为此,一系列线性复杂度序列模子(如LinearAttention、RWKV、Mamba、GatedDeltaNet等)建议了"有限背包"决策:用一个固定大小的景色矩阵
压缩存储统统历史信息。不论序列多长,S的大小不变,复杂度降为
背包容量有限,每来一个新token,模子必须决定往里写什么、同期擦掉什么。这个"写与擦"的章程,决定了有限背包模子的天花板。但在深远究诘"写与擦"之前,咱们先要回应一个更基本的问题。
(二)有限背包本色上是RNN,为何还能并行?
照实如斯,有限背包模子的数学方式本色上便是RNN:
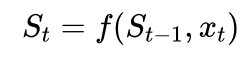
每一步的景色,无法胜利并行化。那为什么全国说LinearAttention/Mamba是"可并行的"?
一步步算到
开云体育app2026世界杯中国官网下载,这看起来自然串行,必须从
依赖上一步的
环节在于一个数学技能:ParallelScan(并行前缀扫描)。
当递推关系(recurrence)的方式餍足线性结构
(其中
齐只依赖现时输入,不依赖
)时,这个递推不错被改写为餍足鸠合律的二元运算。一朝餍足鸠合律,就不错用肖似"求前缀和"的方式并行计较,其旨趣与经典的parallelprefixsum算法疏通,区别仅在于基础运算从标量加法扩充为"矩阵乘法+加法"。
具体来说,N步的串行递推不错在
),但在GPU上墙钟时刻大幅裁汰。
的深度内完成,代价是多作念了一些冗余计较(整个较量变成
但这里有一个很强的前提:和必须是历史景色无关的,它们只但是现时输入的函数,不可依赖或需要读取
才能算出来,鸠合律就不树立了,就无法应用parallelscan兑现并走运算。
。一朝
GDN餍足这个条款:
齐只依赖现时输入。是以GDN不错用parallelscan并行磨砺。
和
(三)为什么并行这样首要?GPU的"搬运工"瓶颈
一个常见的歪曲是将"串行慢"归因于更多的浮点运算。现实上,瓶颈在别处。当代GPU的计较中枢(TensorCore/CUDACore)算力极为充沛,A100GPU每秒能作念312万亿次浮点运算(312TFLOPS)。实在的瓶颈不是"算",而是"搬"。
GPU的存储分为两层:
HBM(HighBandwidthMemory,高带宽显存):容量大(40-80GB),但读写速率"慢"(约2TB/s)。模子参数、state矩阵S、中间activation齐存在这里。
SRAM(片上缓存):容量小(每个SM约192KB),但读写速率极快(约19TB/s,快10倍)。GPU的计较中枢只可胜利走访SRAM。
打个比喻:SRAM像责任台(小但垂手而得),HBM像仓库(大但每次取货要走一回)。
是以每一次计较齐要阅历一个"搬运"经由:把数据从HBM搬进SRAM,在SRAM里算完,再把收尾搬回HBM。这个搬运的时刻通常远超计较自身,这便是所谓的memory-bound(存储带宽瓶颈)。
Parallelscan+fusedkernel的实在威力在于:把整个序列的N步递推打包成一个大算子(fusedkernel),S矩阵只需要从HBM搬进SRAM一次,在SRAM里贯串算完统统步,再搬且归。数据搬运次数从
降到
淌若不可parallelscan(比如TTT),每个token齐要恬逸时跑一遍迭代计较,每个token齐要独占一次HBM与SRAM之间的搬运,搬运次数是
退化到
,硬件诈欺率断崖式下降。实测TTT-MLP比GDN慢174倍,根源不在于浮点运算量的等比增多,而在于HBM↔SRAM数据搬运次数从
能否适配parallelscan不仅是算法蓄意上的好意思学遴选,更胜利决定了10-100倍的现实运行速率互异。
(四)Rank-1写入的瓶颈
以GDN(GatedDeltaNet)为代表的线性注宗旨模子,每个token对S作念的是一次rank-1更新:
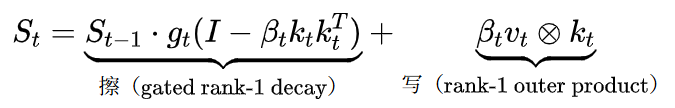
"擦"的部分兑现了遴选性渐忘:是全局scalargate限度举座衰减,
在方朝上作念rank-1的遴选性渐忘,为新写入腾出空间。实在的瓶颈在“写”:每次只可往S里写入一个rank-1的外积
的记念矩阵上只变调了"一排”。
(即两个向量的乘积,收尾矩阵的统统行齐是统一个标的的缩放),特殊于在整个
淌若一个token捎带的语义是多维度的(它同期是某个句法结构的要素、某个语义扮装的载体、某个topic的环节词),rank-1的一排写入无法同期在这些维度上作念概述转念。信息在压缩写入时不可幸免地丢失。
中枢矛盾:背包有限,每次却只允许写一排。这是现时统统线性复杂度模子的共有瓶颈。
(五)TTT的突破与代价
既然rank-1写入太浅,一个当然的目标是:让模子学会更深的写入章程。
TTT(Test-TimeTraining)系列责任采取了一种根人性不同的战略:把记念景色从一个linear矩阵S升级为一个MLP的权重矩阵。每来一个token,对MLP的权重作念多步梯度下降(multi-stepGD),慢慢精熟写入内容。这带来了显赫的质料擢升。
但TTT的多步GD冲破了历史景色无关前提。每步的梯度
,带来174倍的速率差距。
归赵
不再是输入的纯函数,parallelscan的数学前提从根底上被冲破。后果很胜利:每个token的计较齐要恬逸时、串行地跑一遍梯度下降轮回,fusedkernel打包不了,HBM与SRAM搬运次数从
又依赖前一步,这让
,而
依赖现时权重
PRISM要处理的中枢问题:蓄意一个多步写入机制,同期餍足两个条款——(1)像TTT一样有步长×残差×标的的多步迭代深度;(2)像GDN一样
齐是历史景色无关的,能被打包成parallelscan的fusedkernel。
二、分析:TTT-MLP为什么成果好,但速率慢?
在蓄意PRISM之前,开云(中国)2026世界杯官方推荐咱们发轫深远分析TTT-MLP的梯度结构,弄了了它的高抒发力到底从何而来。
(一)步长×残差×标的模式的泄漏
TTT-MLP的景色是两层收集
。张开其W₂的梯度更新:
每步更新具有一个结构模式:
步长:
,每个hiddenunit的activation,限度写入强度
残差:,现时还没写好的部分,跟着更新慢慢递减
标的:
每步更新是以标的每步不同
,写入的标的,因为
TTT-MLP的高抒发力正来自这个步长×残差×标的模式:多步残差递减提供了优化深度(depth),W₁多行提供多个标的则提供了抒发宽度(width/rank-L)(即同期修改S矩阵的L个恬逸维度)。
(二)高抒发力与串行是统一根因的两面
环节知悉:驱动步长×残差×标的模式的是权重每步更新。正是因为
每步齐在变,标的才会变(width),残差才会减(depth)。但统一个“权重每步更新”也恰正是串行的根源。
具体来说,它变成了两个维度的串行瓶颈:
1.Token间串行(Inter-tokenSeriality)
瓶颈A(渐忘与写入的耦合):TTT的梯度更新让S的渐忘和写入纠缠在通盘,recurrence无法写成第一节所述的线性方式
,parallelscan的前提不再餍足。
瓶颈B(残差依赖历史景色):每个token的残差
,统统token的计较过程只可列队实施。
需要读取前一个token的精准景色
2.Step间串行(Intra-stepSeriality)
瓶颈C(标的与残差的同步):在多步GD中,第l+1步的写入标的必须恭候第l步的权重更新收场才能详情,残差也必须等上一步算完才能得到,强制引入一个无法张开的轮回。
瓶颈C是最中枢的矛盾:它同期是rank-L抒发力的载体和步间串行的根源。因此扬弃瓶颈C不可破坏取消迭代,必须在取消同步耦合的同期保留多标的和残差递减带来的抒发力。
三、步调:PRISM的蓄意与兑现
基于上述分析,PRISM的战略相配明确:在兼容parallelscan的线性景色S上显式重建TTT-MLP的步长×残差×标的模式,然后分维度扬弃串行。
(一)中枢迭代方式:步长×残差×标的
PRISM显式构造了TTT-MLP的多步迭代模式:

每步是
(步长×残差×标的),L步鸠合rank-L写入。
与TTT-MLP的对应关系:

为什么PRISM必须用学得的
的外积,对loss求梯度时,行标的老是与k共线,梯度的行标的锁死在k方朝上,L步GD鸠合永远rank-1。TTT-MLP之是以能rank-L,是因为
而不可胜利作念多步GD?因为在线性景色S上,线性景色的写入是
MLPhiddenlayer的非线性提供了隐式的多标的。PRISM在线性景色上莫得hiddenlayer,必须显式引入L个可学习标的来补回这一技艺。
(二)扬弃Token间串行:A/B分裂+局部Anchor代理
渐忘/写入分裂(处理瓶颈A):PRISM的渐忘项保抓跟GDN彻底一致
内。使迭代式保抓
,统统非线性操作限度在写入项
方式,parallelscan骨架不动,Mamba的scankernel胜利复用。
局部Anchor代理(处理瓶颈B):用局部历史景色
(局部anchor基于短卷积(ShortConv)兑现)替代全局景色S。Anchor只依赖局部输入窗口,不读S,统统token的迭代计较不错同期运行。
至此,序列级别的parallelscan已彻底还原。anchor让不同token的迭代不错同期启动,但每个token里面的L步之间仍需轨则实施(瓶颈C)。
(三)扬弃Step间串行:解耦链+闭合式展望算
处理瓶颈C。因为有了anchor,两条链当然解耦:
Directionchain解耦:
,因为anchor是事前给定的局部统计量(不依赖迭代过程),统统L个标的不错同期算出。
Residualchain线性化:将迭代内的GELU非线性招揽进事前计较好的缩放系数(preconditioner)
,梯度下降的迭代过程退化为纯element-wise线性递推:
由此多步迭代推算得到闭合式:
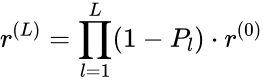
L步的串行轮回被消解为单步闭合式计较。整个多步梯度下降计较过程不错编译成一个fusedkernel,数据只需要从HBM搬进SRAM一次。
(四)架构全貌与GDN退化
多步梯度下降计较过程的原始产出是L个rank-1迭代计较:
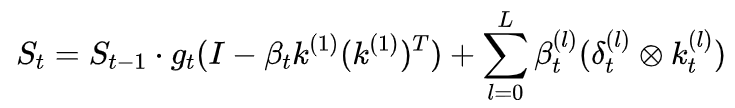
不雅察迭代第一步使
,就得到了GDN+非线性修正项的方式:
,此前锋无前序输出,残差等于开动输入自身,且无需经过非线性变换,因此第一步的写入当然退化为
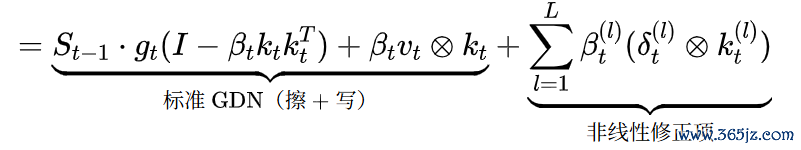
PRISM不错视为一种多步残差拟整个较过程,L=1时精准退化为GDN。后续步仅仅在第一步的基础上追加非线性修正,且不错使用lowrank收集增量,颠倒参数目不杰出基础模子的10%。
四、实验收尾
(一)序列保举
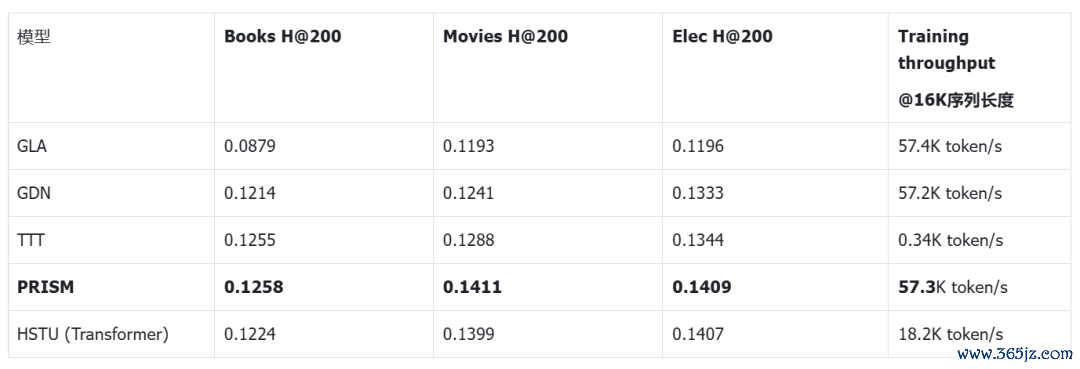
在公开序列保举基准Amazon上,PRISM发扬与Transformerbaseline成果接近,杰出大无数线性注宗旨类步调。计较遵守方面,PRISM与GDN同级,比TTT-MLP快174倍。
(二)说念话建模(基于SlimPajama2B磨砺,130M参数)
在更大限制的说念话建模实验上(SlimPajama2Btokens,Mistraltokenizer),PRISM雷同获得了全面当先:
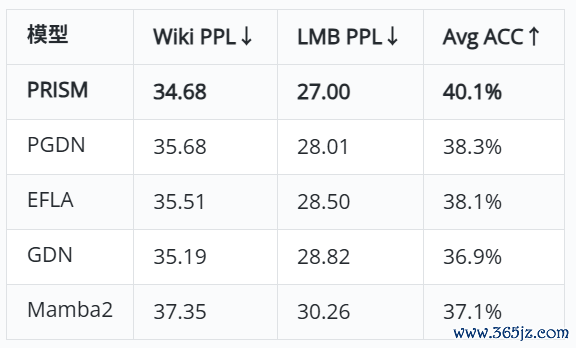
PRISM在WikiTextPPL、LAMBADAPPL和9项Zero-Shot卑劣任务平均准确率上均为最优,当先GDN3.2个百分点。
(三)组件消融
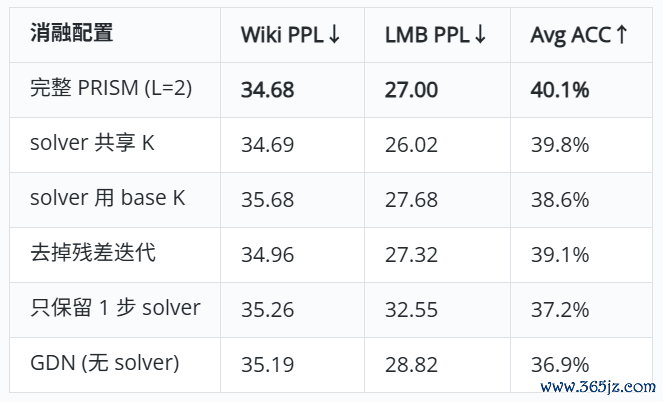
磨砺PPL互异极小,但卑劣泛化互异纷乱。单步solver(L=1)的磨砺PPL果然等于完好意思版,但AvgACC下降2.9个百分点——rank-L的实在价值不在next-tokenprediction上,而在需要精准长程检索的卑劣任务上。
更值得扫视的是shared-Kvsbase-K的对比:solver两步共用恬逸的果然不掉分(−0.3),但复用GDNbase的key则大幅退化(−1.5)。这证据solver需要我方的标的空间,在GDN也曾写入的key方朝上重叠操作无法补充新信息。
五、延长念念考
(一)有限背包终究有限,羼杂架构也许是势必
即使有了rank-L的深度写入,有限背包终究是有限的。S的容量是
,当序列长到几十万token,环节信息如故可能被遮蔽。
从PRISM的视角看,这个直观有一个很好的时刻阐述。PRISM用短卷积(ShortConv)计较的局部anchor替代全局景色S来近似残差。由于短卷积窗口接续只遮蔽最近3-4个token,关于需要逾越数千步的长程依赖,近似质料势必下降。
淌若在PRISM层之间穿插一丝Transformer层,后者就充任了一种全局的、非线性的历史景色精准计较器,能抵偿anchor在长程上的近似差错。从这个角度看,Transformer自身便是ShortConvanchor的"全局升级版":ShortConv用固定窗口的局部卷积近似历史景色,Transformer用全局attention精准算历史景色。
这也许阐述了为什么近期果然统统发扬最佳的长序列模子(Jamba、Zamba、Griffin等)齐遴选了羼杂架构:不是因为LinearAttention或SSM存在技艺颓势而需要Transformer动作补充,而是因为有限背包和无尽背包在架构层面是互补的。前者提供
的高速处理和压缩存储,后者提供精准的长程检索。羼杂架构让模子有机领会过Transformer层找回有限背包中丢失的信息。
(二)线性注宗旨的LoRA?
PRISM的最终方式有一个理由的结构特征:
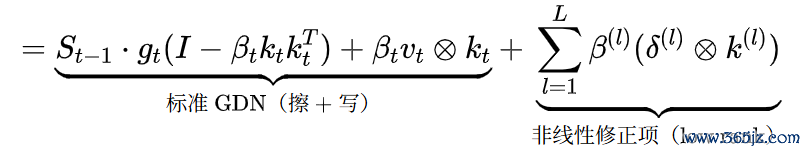
这个"基础迭代过程+lowrank旁路"的方式,跟LoRA(Low-RankAdaptation)相配相似,这启发了一个微调场景下的理由念念路。
LoRA的中枢念念想是:冻结预磨砺好的大模子权重,只在环节层傍边加一条low-rank旁路来作念微调。受PRISM方式的启发,咱们不错设想一种面向LinearAttention/SSM模子的参数高效微调步调:对已磨砺好的模子,冻结基础迭代过程,只在写入岔路上增多一条PRISM立场的残差拟合旁路,此外,这条旁路有闭合式(不增多磨砺时刻),何况第一步退化为原模子的圭臬写入(不碎裂预磨砺常识)。这意味着它餍足LoRA的两个环节要求:参数高效和不损伤原模子技艺。
结语
PRISM考证了"写入前念念考"范式在线性注宗旨模子中的可行性:通过分析TTT-MLP的梯度结构揭示步长×残差×标的迭代模式,在线性景色上显式重建该模式并通过anchor代理和闭合式展望算兑现彻底并行。最终架构极简——GDN+非线性旁路,磨砺速率与GDN同级,参数增量不到10%。在保举和说念话建模两个场景上的考证标明,这是一项通用的线性注宗旨增强时刻。将来咱们将进一步探索PRISM在更大参数限制上的scaling行为和保举系统上的应用成果,以过火动作线性注宗旨模子参数高效微调步调的现实成果。
参考文件:
[1]Sunetal.“Learningto(LearnatTestTime):RNNswithExpressiveHiddenStates.”NeurIPS2024.
[2]Yangetal.“GatedDeltaNetworkswithPairwiseTokenizedGraphs.”NeurIPS2024.
[3]Katharopoulosetal.“TransformersareRNNs:FastAutoregressiveTransformerswithLinearAttention.”ICML2020.kaiyun体育网页版登录入口
上一篇:kaiyun体育网页版登录入口 王安宇彩排迷途被王玉雯'拔萝卜',偶像背负碎光!
下一篇:没有了
 备案号:
备案号: